

教研成果
相关课程:《信息检索》
为了解决基于Web页面的内容自动提取工作,以及提高信息发布和共享的程度,我们找到了一套行之有效的解决方案,开发了“新闻收割机系统”。新闻收割机是一个交互式的Web页面自动采集、格式化存储与定制发布系统。本系统中,首先确定要抽取内容的Web网站,然后划分该网站的信息源类别,对该网站的结构进行初步分析,并利用html分析定位器分析标题列表页,这个过程需要用户设置信息源URL和相关待匹配信息,并由此产生相关标题定位信息。再利用html分析定位器分析内容显示页,这个过程需要用户设置测试也URL和待匹配信息,并由此产生内容定位信息。Html内容抽取工具利用已获得的标题和内容定位相关信息产生抽取配置文件,并且利用这个配置文件来抽取指定内容。完成内容抽取的工作之后,再利用该工具生成文档发布。
新闻收割机是一套细粒度的网络信息格式化抽取框架,集成了信息采集、格式化提取、分类、聚类等信息处理工具。其核心功能包括:网站自动采集、网页自动抓取、网页清洗、对象智能识别、正文自动抽取、关键词提取、自动分类聚类、多粒度、细粒度检索。针对不同的网页结构,只需要配置简单的采集规则即可实现数据的细粒度抽取。
新闻收割机系统解决了Web数据抽取问题,它提供纯粹、不含杂质的数据,适合作为一种数据交换方式由计算机来处理,进而发挥更大的价值。由此突破了HTML的种种限制,可以在数据分析、专业信息服务、竞争情报领域发挥作用。图1是新闻收割机的潜在的应用领域。
为了解决基于Web页面的内容自动提取工作,以及提高信息发布和共享的程度,我们找到了一套行之有效的解决方案,开发了“新闻收割机系统”。新闻收割机是一个交互式的Web页面自动采集、格式化存储与定制发布系统。本系统中,首先确定要抽取内容的Web网站,然后划分该网站的信息源类别,对该网站的结构进行初步分析,并利用html分析定位器分析标题列表页,这个过程需要用户设置信息源URL和相关待匹配信息,并由此产生相关标题定位信息。再利用html分析定位器分析内容显示页,这个过程需要用户设置测试也URL和待匹配信息,并由此产生内容定位信息。Html内容抽取工具利用已获得的标题和内容定位相关信息产生抽取配置文件,并且利用这个配置文件来抽取指定内容。完成内容抽取的工作之后,再利用该工具生成文档发布。
新闻收割机是一套细粒度的网络信息格式化抽取框架,集成了信息采集、格式化提取、分类、聚类等信息处理工具。其核心功能包括:网站自动采集、网页自动抓取、网页清洗、对象智能识别、正文自动抽取、关键词提取、自动分类聚类、多粒度、细粒度检索。针对不同的网页结构,只需要配置简单的采集规则即可实现数据的细粒度抽取。
新闻收割机系统解决了Web数据抽取问题,它提供纯粹、不含杂质的数据,适合作为一种数据交换方式由计算机来处理,进而发挥更大的价值。由此突破了HTML的种种限制,可以在数据分析、专业信息服务、竞争情报领域发挥作用。图1是新闻收割机的潜在的应用领域。
本软件由寇广增博士等开发。
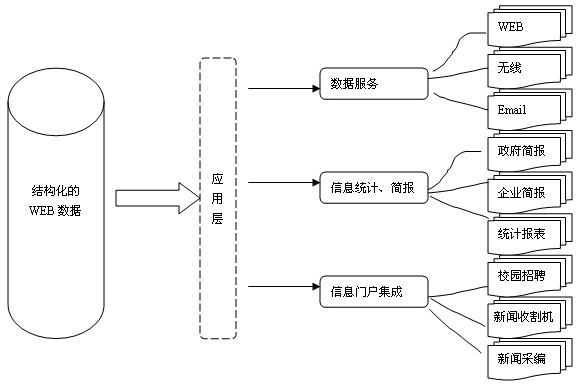
图1新闻收割机潜在应用